Monday, September 8, 2014


ETL Job Design Standards
When using an off-the-shelf ETL tool, principles for
software development do not change: we want our code to be reusable, robust,
flexible, and manageable. To assist in the development, a set of best practices
should be created for the implementation to follow. Failure to implement these
practices usually result in problems further down the track, such as a higher
cost of future development, increased time spent on administration tasks, and
problems with reliability.
Although these standards are listed as taking place in ETL
Physical Design, it is ideal that they be done before the prototype if
possible. Once they are established once, they should be able to be re-used for
future increments and only need to be reviewed.
Listed below are some standard best practice categories that
should be identified on a typical project.
- Naming Conventions that will be used across the ETL integration environment.
- Release Management: The ETL version control approach that will be used; including version control within the tool itself.
- Environments: How the ETL environment will be physically deployed in development, testing and production. This will generally be covered in the Solution Architecture.
- Failover and Recovery: the strategy for handling load failures. This will include recommendations on whether milestone points and staging will not be required for restarts.
- Error Handling: proposed standards for error trapping of jobs. This should be at a standards level, with detail of the design covered explicitly in a separate section of the physical design.
- Process Reporting: status and row counts of jobs should be retrieved for accurate process reporting.
- Notification: Identification is the manner in which information about successful and unsuccessful runs is delivered to the administrator and relevant stakeholders.
- Parameter Management: the ability to manage job parameters across environments so that components can be delivered and run without requiring any modifications.
- Optimization: Standards for improving performance such as parallelism or hash files. The more detailed design aspects of this approach is a separate section of the physical design.
- Reusability: Standards around simplified design and use of shared components.
- Metadata Management: Standards around metadata management as they apply to the ETL design.
Listed below are some of the major standards that apply to
each of these categories.
Contents
|
Naming Conventions
There are a number of types of naming conventions to be used
across the ETL environment. ETL naming conventions are important for giving all
projects a consistent look and feel. A naming convention makes metadata
reporting more successful by making it easy to determine data lineage and to
identify ETL stages within metadata reports and job diagrams.
Typically ETL is executed as a set of jobs, each job
processing a single source data entity and writing it to one or more output
entities. A job is made up of stages and links. A stage carries out an action
on data and a link transfers the data to the next stage.
Below is a suggested set of naming standards.
Vendor-specific considerations could dictate variations from this set.
Job Naming
The job name uses underscores to identify different labels
to describe the job. The following job naming template shows all the types of
labels that can build a job name:
JobType_SourceSystem_TargetSystem_SourceEntity_TargetEntity_Action
The number of labels used depends on the specific
requirements of the project and the nature of the particular job.
- JobType indicates what type of job depending on what ETL tool is being used. Some example job types include Server, Parallel and Sequence. In this instance the job types can be abbreviations such as ser_, par_ and seq_.
- SourceSystem and TargetSystem indicate which database or application or database type owns the source or target entity. This is typically a code or abbreviation that uniquely identifies the system. These are optional labels and are usually included to make job names unique across all folders and projects in an enterprise.
- SourceEntity is a plain English description of what is being extracted. If it is a table or file name the underscores can be removed to form an unbroken entity name. If the source table has a technical encoded name the job name describes it more descriptively.
- TargetEntity is optional and is only used if one type of data entity is outputted from the job. When the ETL job splits data and writes to different tables this label becomes misleading.
- Action is used for jobs that write to databases and describes the action of the database write. Action label is chosen from the list of Database Action Codes below.
Fully qualified job name examples where the job name
identifies the transition between systems:
- par_sap_staging_customers
- par_sap_staging_sales
- par_staging_ods_customers_insupd
- par_staging_ods_customers_ldr
Entity-only job name examples where the name identifies what
entity transformation is occurring:
- customers_customertemp
- par_customers
- customers_customerhistory
- customers_insupd
- customers_ldr
In these examples the name of the project and the name of
the folder the job resides in indicates the what source and target system is
being affected. For example, the folder is named SAP to Staging Loads.
Stage Naming
The stage name consists of a prefix that identifies the
stage type followed by a description of the stage.
- The prefix is the first two letters of the stage type or the first two initials of the stage type if multiple words occur.
- For source and target stages the stage name includes the name of the table or file being used.
- For transformation stages the stage name includes the primary objective of the stage or an important feature of the stage.
Link Naming
Links are named after the content of the data going down
that link. For links that write to a data target a suffix indicates what type
of write action from the Database Action Types below.
Database Action Types
This list shows the abbreviations that describe an action
against a target table or file. These abbreviations are used in job names and
link names where appropriate.
- Ins - Insert
- Upd - Update
- Ups - Upsert, performs either an update or an insert
- Del - Delete
- Aug - Augment
- App - Append
- Ldr - Database Load
A combination of action types can be included in a name if
they are performed in different stages, e.g., Customer_InsUpd.
Parameter Management Standards
This section defines standards to manage job parameters
across environments. Jobs should use parameters liberally to avoid hard coding
as much as possible. Some categories of parameters include:
- Environmental parameters, such as directory names, file names, etc.
- Database connection parameters
- Notification email addresses
- Processing options, such as degree of parallelism
The purposes of Parameter Management are:
- Each environment’s staging files, parameter lists, etc. are isolated from other environments.
- Components can be migrated between environments (Development, Test, Production, etc.) without requiring any modifications.
- Environmental values, such as directory names and database connection parameters, can be changed with minimal effort.
Parameters must be stored in a manner which is easy to
maintain yet easy to protect from inadvertent or malicious modification. Routines
are created to read the parameters and set them for job executions.
Performance Optimisation Design Standards
Performance Optimisation defines standards for optimising
performance, such as using parallelism or in-memory lookup files. These design
aspects are usually vendor-specific.
Reuse Standards for Common Jobs
Reuse standards define the approach for using shared
components to simplify design. Identification of common jobs during physical
design is the next iteration on the logical design task of identifying common
jobs. As we move to physical design, opportunities for re-use will become more
apparent. At this stage, common job opportunities should be identified and the
team should be made aware of their capabilities.
Data Sourcing Standards
This section defines standards related to Data Sourcing,
which involves reading data from a source file or database table or collecting
data from an API or messaging queue. For database sources, it can involve a
join query which combines several tables to provide a flattened source. For
example, when the data source is a database table the following is recommended:
- Try to filter out rows that are not required. Database SQL filters can be very efficient and reduce the volume of data being brought onto the ETL server.
- Where table joins and sorts are appropriate in a source query, it may be more efficient to have the database server do this processing rather than the ETL server.
- Do not alter the metadata of the source data during this phase. Column renames and column functions in a sourcing ETL statement work but this technique can hide the derivations from metadata management and reporting and break the chain of data lineage.
When the data source is a text file consider the following:
- Comma separated files can be unreliable where the source data contains free text fields. Data entry operators can add commas, quotes and even carriage-return characters into these fields which disrupts the formatting of the file.
- Complex flat files from a mainframe usually require a definition file in order to be readable by ETL tools. Files from COBOL applications are defined by a COBOL definition file. ETL tools use the definition file to determine the formatting of the file.
Data Loading Standards
Data Loading Standards define a common approach for loading
data into the target environment that impact performance, data integrity and
error handling. For database targets there are multiple types of write actions:
- Insert/Append
- Update
- Insert or Update
- Update or Insert
- Delete
Usually the stage also has options to clear or truncate the
table prior to delivery. The order of update/insert insert/update is important
from a performance point of view. For an insert/update action the job attempts
to insert the row first, if it is already present it does an update. The order
depends upon whether data is present or absent. Database-specific options could
include things like transaction size, truncation before insert, etc. For
non-database targets the standards for file, messaging, API or other output are
defined.
Exception Handling Standards
This section outlines standards for common routines and
procedures for trapping errors and handling them and reporting process
statistics. The objectives are to:
- Find all problems with a row, not just the first problem detected.
- Avoid row leakage, where rows are dropped or rejected without notification.
- Report all problems.
- Report process statistics.
- Interface with other processes which work to resolve exception issues.
It also defines what error detection mechanisms are
required, and what is to be done when an exception is detected.
Process Reporting and Job Statistics Standards
Process Reporting Standards define how status and row counts
of jobs are to be retrieved, formatted and stored for accurate exception and
process reporting.
Notification Standards
Notification Standards define how information about
successful and unsuccessful runs is delivered to the administrator and relevant
stakeholders
Scenario: Get the max salary from data file ( Seq file )
We know that max function is use to get the max value in a column of a table, but here you have to design a datastage job which get the max value from seq file.
Input Seq File :
FIRSTNME,SALARY,WORKDEPT
EILEEN, 0089750.00,E11
EVA, 0096170.00,D21
JOHN, 0080175.00,E01
CHRISTINE, 0152750.00,A00
SALLY, 0098250.00,C01
IRVING, 0072250.00,D11
THEODORE, 0086150.00,E21
MICHAEL, 0094250.00,B01
Output File
0152750.00
Solution Design :
a) Job Design :
Below is the design which can achieve the output as we needed. In this design, we are reading the data from flat file, generating a dummy column in column generator stage, doing aggregate on that and sending the output to seq file.

b) Column Generator Stage :
In column generator stage, we will generate a column DUMMY having value 'X' for all the rows which we are reading from the seq file

For generating value 'X' for all the rows, need to change extended
metadata for the column DUMMY. Set generator for Cycle algorithm with
value 'X'

Map the Salary and DUMMY column to output of Column Generator stage

c) Aggregator Stage :
In aggregator stage, we will aggregate on the DUMMY column and calculate the MAX of Salary.

and Map the Max Salary to Output .

Peek Stage
The Peek stage is a Development/Debug stage. It can have a single input link and any number of output links.
The Peek stage lets you print record column values either to the job log
or to a separate output link as the stage copies records from its input
data set to one or more output data sets.
1. Design :
We are using below design to demonstrate the functionality of PEEK stage
in datastage. Job design is having 3 stages, Row Generator , data
source, for generating the dummy data for the job. Here, we can use any
data source whether it is DB, dataset or flat files. Transformer, just
as a stage, creating negative values of source data. Peek for Peeking
:-)

2. Row Generator Stage Properties :-
We are generating 100 records via Row Generator stage. Just set the Number of Records to 100 as shown below ...

and define the metadata......

3. Transformer Stage Properties :-
Whatever the data has been generated by source, we are simply negating
by multiplication of -1. Here, we dont need this stage but for shake of
doing something I have used here. :-)
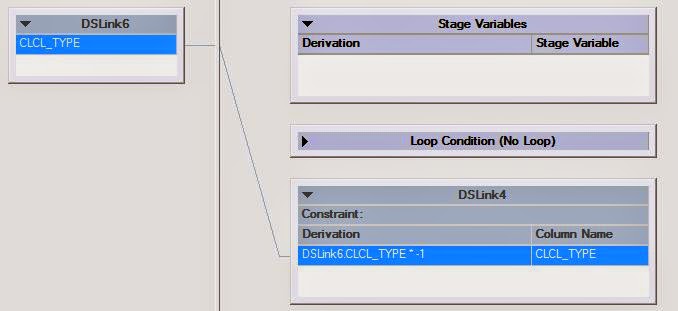
4. PEEK Stage Properties :-
In English language the meaning of PEEK word is "To glance quickly".
Peek stage is doing same in datastage, we are using this stage for
debugging and looking the intermediate data if needed.
In our scenario, we have used below setting for our Peek Stage.

- COLUMNS - Same for COLUMN properties, need to define whether you need all or some column. In case of "PEEK All Input Column = FALSE" , need to defined which column you needed in output.
- PARTITION - Same as above
- OPTION - Here, you can select where you want the output , In a file or DS job log and You needed the column names along with data or not.
5. PEEK Stage Output
Below I have attached a screen shot from DS job log where

Double click any entry and vola :) , You can see the data in job log.
For our design, we are generating negative integer values which we can
see in output.

Scenario: To get the Unique and Duplicates values from Input Data
Input :
There is a input file which contains duplicates data, Suppose :13
22
95
37
78
87
29
33
33
13
12
87
21
32
13
In this file :
Unique values are : 22 95 37 78 29 12 21 32
Duplicate values are : 13 33 87
Now, we need 3 kind of outputs:
Job1:
We need 2 o/p fileo/p1 --> Contains Uniq values
o/p2 --> Contains Duplicate Values ( each once ) i.e - 13 33 87
DataStage Scenario - Design 2 - job1
Solution Design :
a) Job Design :
Below is the design which can achieve the output as we needed. Here, we are reading seq file as a input, then data is passing through Aggregator and Filter stage to achieve the output.

b) Aggregator Stage Properties
Input data contains only one column "No" , In Aggregator stage, we have group the data on the "No" column and calculate the rows for each Key ( No ).

When we have used the "Count Rows" aggregation type, it will generate a new column which contain the count for each Key (No). Here we have given the column name - "count" and assigned to output as below.

c) Filter Stage Properties
In Filter stage, we put 2 where condition count=1 and count>1. and assigned different output files to both conditions.

Assigned the data ( column No ) to output tab.

d) Output File
We got two output from the jobs
i) Contains where count=1 ( unique values in input )
ii) Contains where count>1 ( dups values in input )
Job2
We need 2 o/p fileo/p1 --> Contains Uniq values
o/p2 --> Contains Duplicate Values ( no of times they appear ) i.e - 13 13 13 33 33 87 87
DataStage Scenario - Design2 - job2
Solution Design :
a) Job Design :
In job design, we are using Copy, Aggregator, Filter and Join stage to get the output.

b) Copy Stage Properties :
Simply map the input to both link output. first link goes to Aggregator and second link goes to Join stage.
c) Aggregator Stage Properties :
Input data contains only one column "No" , In Aggregator stage, we have group the data on the "No" column and calculate the rows for each Key ( No ).
d) Filter Stage Properties :
In Filter stage, we put 2 where condition count=1 and count>1. and assigned different links to both conditions.
From filter Stage, first link (count=1) map to output file ( which contains the unique records )
and second link we map with Join stage.
e) Join Stage Properties :
In join stage, we join the both input on key column (No).

Output from Join map with second output files which contains all the dups as occur in input.
Job3
We need 2 o/p fileo/p1 --> Contains all values once each i.e - 22 95 37 78 29 12 21 32 13 33 87
o/p2 --> Contains remaining values - 13 13 33 87
DataStage Scenario - Design2 - job3
Solution Design :
a) Job Design :

b) Sort Stage Properties :
In sort stage, we sort the data on Key column (no) and generate the change key column.

c) Filter Stage Properties :
filer the data on "Change" column generated in sort stage.
 In filter stage, condition ( change =1) gives you all values (each
once) from input and condition (change=0) gives the all duplicate
occurrence from input.
In filter stage, condition ( change =1) gives you all values (each
once) from input and condition (change=0) gives the all duplicate
occurrence from input.
a) Job Design :
b) Sort Stage Properties :
In sort stage, we sort the data on Key column (no) and generate the change key column.
c) Filter Stage Properties :
filer the data on "Change" column generated in sort stage.
Scenario: Get the next column value in current row
Input file :
Sq, No1,1000
2,2200
3,3030
4,5600
Output File :
Sq, No,No21,1000,2200
2,2200,3030
3,3030,5600
4,5600,NULL
Solution
Design :
a) Job Design :
Below is the design which can achieve the output as we needed. Here, we are reading seq file as a input, then data is passing through a Sort and Transformer stage to achieve the output.
a) Job Design :
Below is the design which can achieve the output as we needed. Here, we are reading seq file as a input, then data is passing through a Sort and Transformer stage to achieve the output.

b) Sort Stage Properties
in
Sort stage, we will sort the data based on column “Sq” in
descending order.

c)
Transformer Stage Properties
Here,
we took 2 stage variable : StageVar, StageVar1
and their derivations are -
and their derivations are -
- StageVar1
= StageVar
DSLink6.No = StageVar1

d)
Output File
Before capturing the data into Sequential file. We will sort the data again in ascending order to get the output as we needed.
Before capturing the data into Sequential file. We will sort the data again in ascending order to get the output as we needed.

Dummy Data Generation using Row Generator
By default the Row Generator stage runs sequentially, generating data in a single partition. You can, however, configure it to run in parallel and meaningful data.
a) Job Design :

b) RowGenerator Stage :
- Double click on Stage
- Fill the properties tab, Fill the No of Rows you want to generate. ( Here I filled 50 )

- Now, clock on column tab and define the column you needed on o/p file, Need to define Column Name, type, length etc.

-- Now Here we took our Magic Step :-) We will edit the Meta Data of Column

-- When you double click on Column 1 (Name), This Window will open, As you can see, we can edit a lot of metadata of a column here.

-- We want to generate some meaningful data, so we use the Generator properties here.
Here we selected Algorithm ( of data generation ) is Cycle which repeat the data from start to end. and we have passed some values ( Names )

-- Same we will follow for Second Coulmn ( Salary )

- And then Click OK, we are done with Column Generator Stage.
c) Seq File Stage
- Define the Seq File stage properties here, Like, O/p file location, delimiter, column name, quotes etc in o/p file.
- and Keep it all other tab as it is.

- Now Save the job design,Compile and RUN.
Output File will look like below -

Here, as we can see, Name is repeating in a Cycle again n again and
Salary column also follow the same. So here we have some meaningful data
for our dummy job test.
Subscribe to:
Posts (Atom)