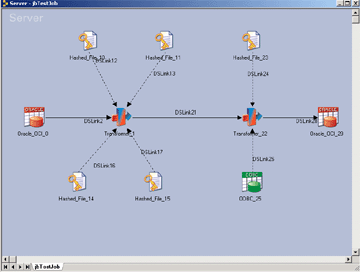
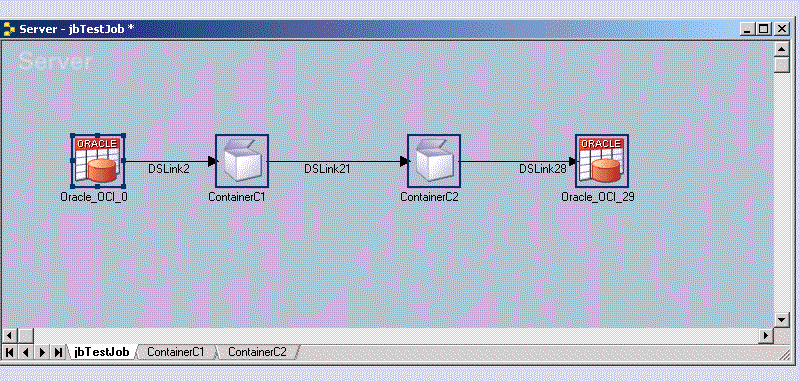
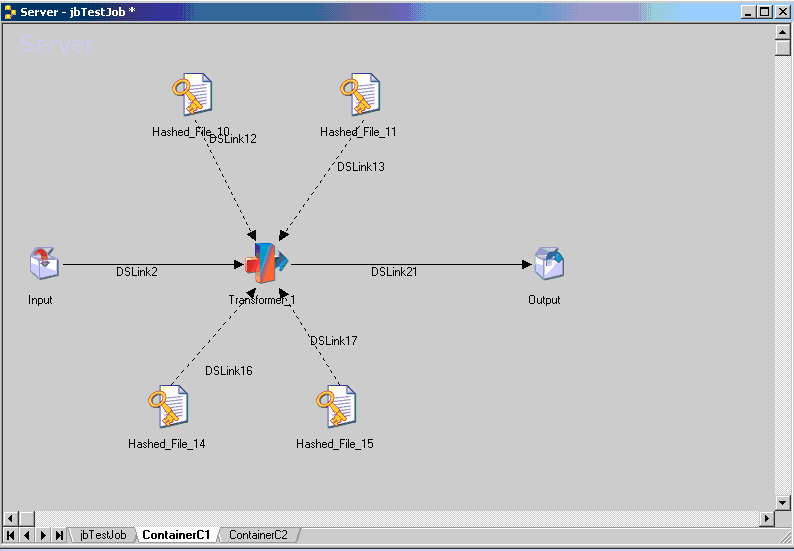
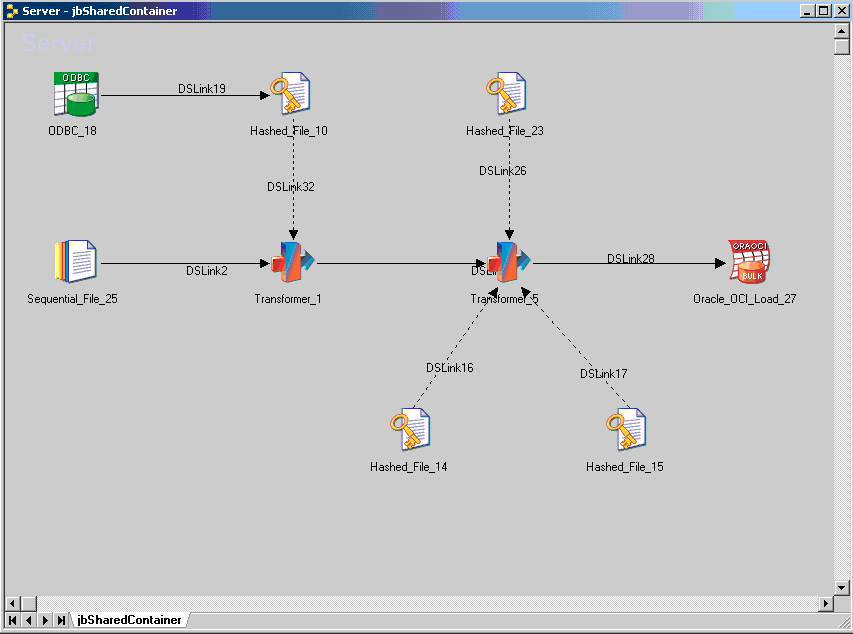
Predicting hardware resources needed to run DataStage jobs in order to meet our processing time requirements can sometimes be more of an art than a science. With new sophisticated analytical information and deep understanding of the parallel framework, IBM has added Resource Estimation to DataStage (and QualityStage) 8.0.We can estimate and predict the resource utilization of parallel job runs by creating models and making projections in the Resource Estimation window. A model estimates the system resources for a job, including the amount of scratch space, disk space, and CPU time that is needed for each stage to run on each partition. A model also estimates the data set throughput in a job.
STEPS OF RESOURCE ESTIMATION:-
- Step 1: Open a job from the Repository.
- Step 2: Choose the option Resource Estimation which is available in the toolbar.

Figure 1 - Choose Resource Estimation from toolbar
- Step 3: Create a resource model.
There are two types of resource models:
Static. The static model does not actually run the job to create the model. CPU utilization can not be estimated, but disk space can be. The record size is always fixed. The “best case” scenario is considered when the input data is propagated. The “worst case” scenario is considered when computing record size.
Dynamic. The Resource Estimation tool actually runs the job with a sample of the data. But CPU and disk space are estimated. This is a more predictable model to use for estimating.
To create a model:
- Open a job in the Designer client, or select a job in the Director client.
- Open the Resource Estimation window by using one of the following methods:
- In the Designer, click File →Estimate Resource.
- In the Director, click Job →Estimate Resource.
- Click the Resource Estimationtoolbar button.
The first time that you open the Resource Estimation window for a job, static model is generated by default. - Click the Model toolbar button to display the Create Resource Model options.
- Type a name in the Model Name field. The specified name must not already exist.
- Select a type in the Model Type field.
- If you want to specify a data sampling range for a dynamic model, use one of the following methods:
- Click the Copy Previous button to copy the sampling specifications from previous models, if any exist.
- Clear the Auto check box for a data source, and type values in the Fromand To fields to specify a record range.
- Click Generate.Figure 2 - Create Resource Model

- Step 4: Project the resources required to execute the job based on varying data volumes for each input data source.To make a projection:
- Open a job in the Designer client, or select a job in the Director client.
- Open the Resource Estimation window by using one of the following methods:
- In the Designer, click File →Estimate Resource.
- In the Director, click Job →Estimate Resource.
- Click the Resource Estimationtoolbar button.
- Click the Projection toolbar button to display the Make Resource Projection options.
- Type a name in the Projection Namefield. The specified name must not already exist.
- Select the unit of measurement for the projection in the Input Units field.
- Specify the input size upon which to base the projection by using one of the following methods:
- Click the Copy Previous button to copy the specifications from previous projections, if any exist.
- If the Input Units field is set to Size in Megabytes, type a value in theMegabytes (MB) field for each data source.
- If the Input Units field is set to Number of Records, type a value in the Records field for each data source.
- Click Generate.

Figure 3 - Make resource projection
- Step 5: A projection is then executed using the model selected. The results show the total CPU needed, disk space requirements, scratch space requirements, and more.
- To generate a report:
- In the Resource Estimation window, select a model in the Models list.
- Select a projection in the Input Projections list. If you do not select a projection, the default projection is used.
- Click the Report toolbar button.
[By default, reports are saved in the following directory:
“C:\IBM\InformationServer\Clients\Classic\Estimation\server_name\project_name\job_name\html\report.html”]Figure 4 - Resource Estimation Report

- Step 6: Graphical charts are also available for analysis, which allow the user to drill into each stage and each partition.Figure 5 - Graphical Charts Sample

Conclusion
So, here we can see through resource estimation facility of DataStage we can estimate the resources that has been used for execution of any parallel job.